Infrastructure overhaul of 2017
December 2017
lordkator
Infrastructure overhaul of 2017
As many of the community are aware on August 9, 2017 Basilisk experienced an extended unplanned outage due to disk issues on the server. As that process unfolded TheAnswer promised the community we would share what happened and what we planned to do about it.
TL;DR (Summary)
We lost disks on the original Basilisk server causing us to do manual work to restore the game server databases, this work resulted in the restoration of the server on August 16, 2017.
As of December 4, 2017 all services have been moved to a new environment that is much more robust, has considerably more resources and is designed for us to handle hardware outages much more easily in the future. Our new environment includes redundant servers, faster internet access, more CPU power, more RAM and improved storage redundancy and speed.
The completion of this migration provides a stable platform for the community for many years into the future.
What happened?
When the original server for Basilisk was deployed in 2006 it was a state of the art machine and had experienced a number of hardware upgrades over the years.
The system was configured with multiple Solid State Disks (SSD) setup to keep two on-line live copies of the data (RAID 1 mirror). The goal of such a setup is that when one disk fails we can replace it before data is lost and rebuild the copies. This setup also provides higher read rates because the system can ask both disks for different data at the same time.
The week before this incident one of the mirrored disks failed, our hosting provider failed to notify us and meanwhile we did not get the emails from the sever alerting us to disk issues. In a sad twist of fate the second disk that was mirroring this failed drive also started to fail a week later. The odds of two disks failing within such a short timeframe are fairly rare.
Because of the size of Basilisk's database (over 600 Gigs) we were doing backups on an ad-hoc basis to the Nova server's disks. This meant any restore would lose significant amounts of player progress. With this in mind TheAnswer worked with low-level filesystem debugging tools to extract the database files from the failing drive. This was a painful, slow process that required many iterations to get the data back to a usable state. Much of it was manual and each step could take many hours to run before the results are known and decisions are made on the next step. After many sleepless nights TheAnswer was able to get Basilisk back online on August 16.
How do we avoid this in the future?
In response to this event we took inventory of all our services and did an analysis of our current setup. As you can imagine after 10 plus years the project had accumulated many services and servers to run our community. This setup was very difficult to maintain due to the many dependencies between various services and the underlying software, operating systems and hardware.
After debating various paths forward the team decided it was time to overhaul our infrastructure. We decided to re-build from scratch on new bare metal servers from packet.net and utilize an open-source technology called kubernetes to manage the services as individual movable containers. We would deploy our servers on top of ZFS storage pools which would allow us to have modern data safety and management tools.
Deploying on packet.net gives us an incredible amount of flexibility, rather than opening tickets and asking for new machines or emailing back and forth we can just launch new resources using the packet.net API. In addition to that we have "reserved" three servers that allow us to run our infrastructure and provide on-line ready to run redundancy for our services.
Containerizing our services and using kubernetes to manage them allows us the ability to quickly re-schedule services on other hardware if we lose a node or it becomes overloaded with work. The industry is rapidly turning to support kubernetes (originally a Google technology) and by standardizing on this system we can leverage other providers if needed in the future or quickly expand our footprint in any of packet.net's datacenters.
By utilizing ZFS for our storage system we are able to make instantaneous snapshots of the data underlying a service. We setup these storage volumes using very high speed non-volatile memory (PCIe NVMe) and join those in redundant and high-speed configurations (RAID 10). For most services we were able to deploy packet.net's block store volumes. These are high-speed (PCIe NVMe) network attached volumes that allow us to quickly move between servers if a server crashes or becomes overloaded with work.
This combination of our hosting, containerization and storage strategy provides us with many options that were not available to us before the overhaul. This investment should power the project's needs for many years to come and will make it easier for the team to manage existing services and provide new and exciting capabilities to the community in the future.
We expect the short term financial impact to be a bit higher as the services transition and overlap plus bandwidth to copy files into the new environment. Over time we predict the costs to be about the same as our previous setup with easily a 10x increase in capacity and capabilities.
Status?
As of December 2, 2017, all services have been moved to the new infrastructure. Basilisk has been happily running on the new hardware since September 24, 2017 and Nova followed not long after that. We have moved everything from forums, support site, jenkins, gerrit and various other servers to the new infrastructure.
We have daily snapshot backups that are pushed to external block store volumes so we can lose a host completely and have worst case one day of lost progression. Meanwhile we have deployed database logging on Basilisk and Nova so that every transaction is saved in storage in a way that we can roll-forward a database crash if needed by re-playing the changes that happend since the prior copy of the database.
We maintain daily snapshots for a week both locally on the server's disks and remotely on blockstore volumes attached over the network.
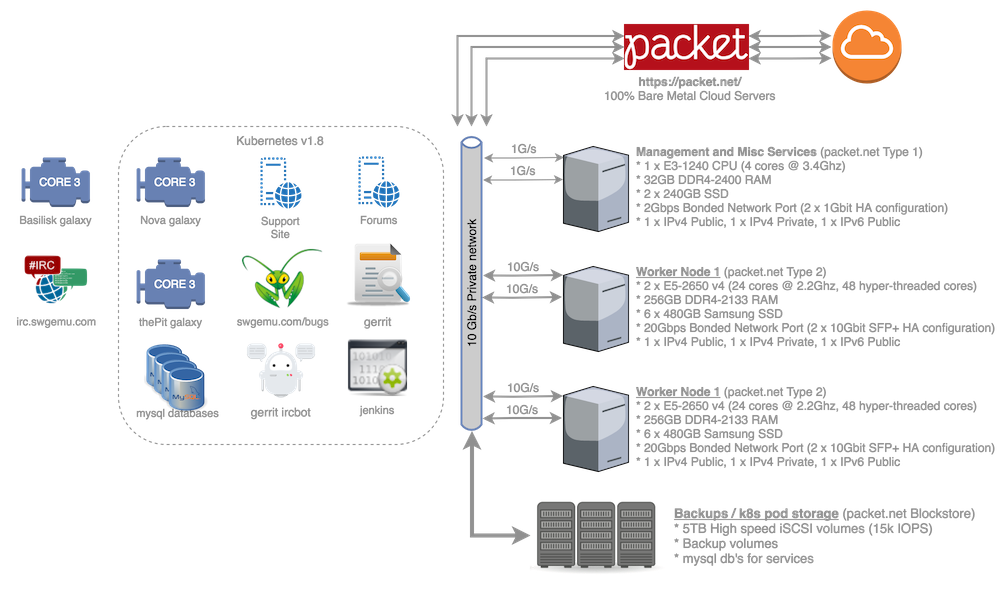
What's it look like?
Here is a simplified diagram of our current environment for your viewing pleasure:
Random Stats- Migrated 16 distinct services
- Over 3 Terabytes of data migrated
- 3,009,329 lines of PHP
- 18,640,175 lines of C++
- 102,682,949 lines of Lua
- 12 copies of sceneobjects.db in various folders
- 4 people actually read this far in this post.
Next Steps
We've started creating alert bots that send messages to a channel the staff can monitor for issues so they can help escalate as needed.
We will be adding more alerts, testing some deep storage solutions (AWS S3 Glacier and the like) and adding more tools so other members of the staff can help with various tasks w/o being Unix admin experts.
~lordkator DevOps Engineer